
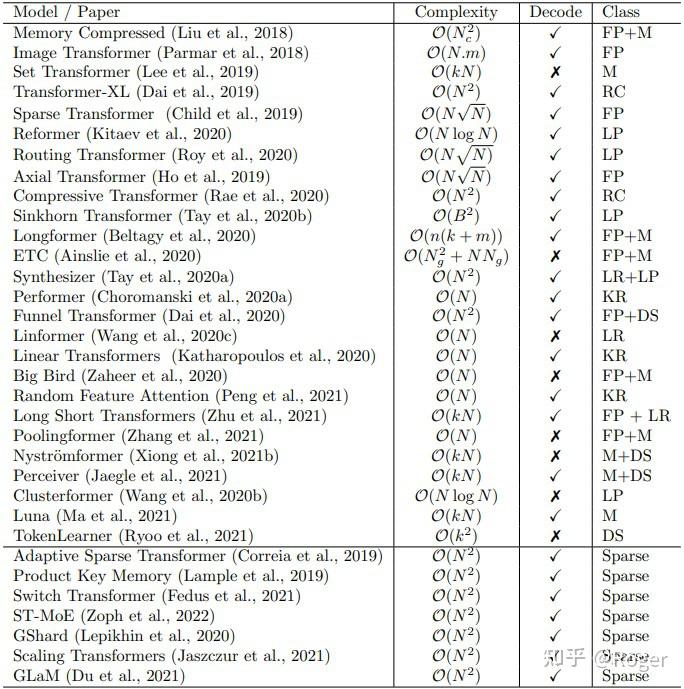
本文主要翻译总结自博客,内容上做了些许扩充,感兴趣的建议看原文。
Transformer 模型在当今NLP的地位自不必说,在CV、多模态等领域,基于 Transformer 也开始崭露头角。但在实际使用中,往往会因为 Transformer 的模型复杂度为而限制了其使用场景。为了能让该模型具备处理更长文本序列的能力,从不同的优化角度出发诞生了许多 Transformer 的变种。这里对这些变种的特点做一个总结和概述。
Transformer 模型可学习参数主要由 embedding matrix,attention 模块两部分组成。Embedding matrix 主要由词表大小及隐层维度
决定,总参数量为
。
对于 Attention 模块的注意力部分,假设注意力头数为。维度为
的输入经过矩阵
,
及
的变换得到对应的 query, key, value 向量表征,这里一个头的
,
,
维度为
,将多个头的参数合并(实际中通过reshape来实现),则
,
,
维度均为
。自注意力的输出会经过一个投影层,模块的输出维度不变,所以这部分参数为
。所以注意力模块的参数数量为
。
Attention部分的输出会经过两层 MLP,输入维度为,中间维度为
,则两层 MLP 的总参数量为:
。总的一个 Attention模块的参数为
。
假设Transformer的模块层数为,那么模型总的参数量为
Transformer 模型的计算/空间复杂度主要由其注意力模块来决定,这也是模型的瓶颈所在。注意力计算公式:
根据上式,若序列长度为,由于每个 token 都需要与所有 token 计算相似性,所以光
这项做矩阵乘的复杂度为
,即为平方复杂度
。
目前有许多针对 Transformer 的优化,用于处理更长的序列,减少内存占用或加速推理。其中四种常见的方法有:
下面详细介绍四种方法及对应的模型变种。
这类工作主要是基于 Segment Level Recurrence 来减少内存占用,以使模型可处理更长的输入序列,是一种分治思想。
原始的 Transformer 模型有着限定长度的注意力范围,每个 token 只可能关注其自身字段(segment)内的其它 token 信息且无法在不同的字段之间传递上下文信息。
Transformer-XL 试图通过重用不同字段之间的隐态表征的方法来解决输入长度限制。此外,该模型还使用了一种新的位置编码。
Segment Level Recurrence 并不是显式地将 dense 自注意力矩阵优化为 sparse,而是像RNN一样使用 recurrent 机制来连接不同的字段。它将来自前一个字段的表征缓存下来,然后作为当前字段的扩展上下文来使用。这一方法将最长文本长度扩大了 N 倍。其中 N 为网络的深度。
Compressive Transformers 是 Transformer-XL 的进一步改进。二者之间最大的区别是后者只保留前一个字段的激活(activation),而前者通过使用二级缓存机制,将过去所有字段的激活都保存了起来。因此,Compressive Transformers 可以处理比 Transformer-XL 更长的文本长度。
稀疏注意力不是在完整的注意力矩阵中计算所有可能的分数对,而是从输入序列中计算有限的分数对以构建一个稀疏矩阵。在选择有限对进行评分方面有几种稀疏模式。常见的包括:

Longformer 使用了多种稀疏注意力模式:它在与序列程度成线性关系的同时,将局部(sliding window attention)与全局(global attention)信息结合了起来。在每个注意力层中,复杂度从减少到
。其中
为输入长度而
为窗口大小。
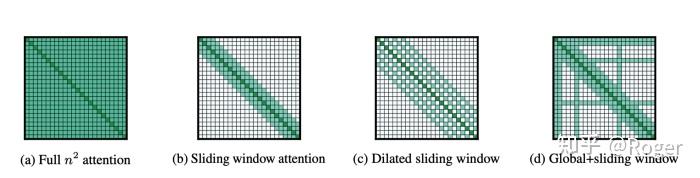
与Longformer 类似,Big Bird也结合了 random attention, sliding window attention 以及 global attention 来构建自己的稀疏性。

上图中的稀疏注意力模式多是基于位置的,这意味着选择从输入序列中选择有限对 tokens/pixels 对。另一种生成稀疏注意力矩阵的策略是基于内容或输入 tokens 的方法。Routing Transformer 和 Performer 是典型的基于内容的稀疏注意力矩阵,基本概念是聚类/分桶。
Routing Transformer的想法是学习动态稀疏注意力模式,避免分配计算和内存来关注与感兴趣的 query 无关的内容。它利用 k-means 聚类来聚类 query 和 keys,因此每个 query 仅关注属于同一个 cluster 的 keys 来创建其稀疏性。
Reformer引入了多种全新的技术,比如 multi-round LSH attention 以及 reservable transformer。与 Routing Transformer 使用 k-means 聚类来减少注意力范围并创建稀疏性的方法类似,Reformer 使用一个基于哈希的相似性度量(multi-round Locality Sensitive Hashing)来高效准确地实现 token 分桶并将它们切块成同样大小来方便并行计算。Reformer 声称可以在单处理器上,仅使用16 GB内存就处理长达一百万词的上下文窗口。总的来说,Reformer 使用的用来减少计算复杂度与内存空间的两个关键技术:
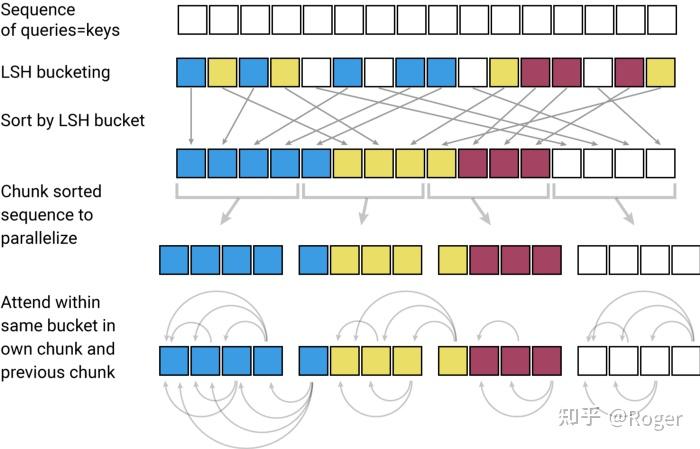
理论上,LSH可以帮助减少复杂度为,但实际中,Reformer只有对输入长度>2048的情况才会显现出收益。此外,multi-round LSH attention 也添加了额外的操作,从而造成了性能下降。
稀疏注意力也有其局限性:
低秩近似和核近似是另一种流行的将自注意力矩阵化简为线性复杂度的方法。总的来说,这类方法关注近似或者化简 QKV attention 中的矩阵乘。Linformer 和 Perceiver 是两个使用低秩近似技巧来做投影的例子,它们声称可以将注意力矩阵优化为线性时间复杂度。
Linformer 通过向 K 和 V 矩阵添加一个投影层,将原始的全注意力点乘运算分解为更小的注意力。具体来说,它将 维的 keys 和 values 投影为
维,即将输入序列的长度投影为一个更短的值,同时保持 key 和 value embedding的维度不变。
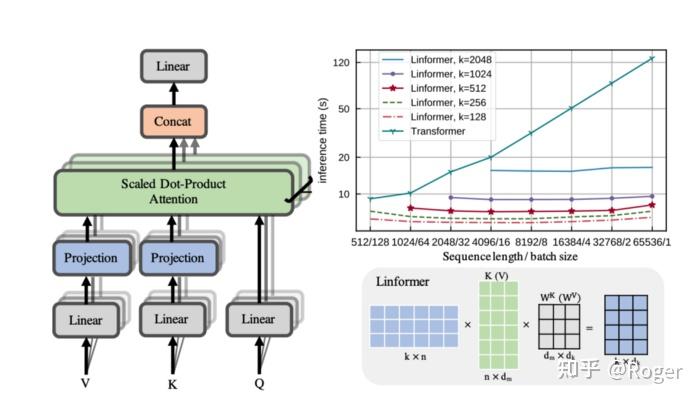
当 比
小很多的时候,Linformer可以显著减少内存占用。此外,Linformer 还引入了其它提高效率和性能的技术:
Performer 在不显式地计算自注意力矩阵的情况下来近似注意力。同类方法还有 Linear Transformer,RFA(Random Feature Attention),Nystr?mformer 使用近似方法来简化 QKV 注意力矩阵计算。
相比于原始注意力矩阵,Performer 首先首先逼近较低秩的随机 Q 和 K 矩阵,然后使用矩阵关联属性以不同的顺序计算最终的注意力。即相比于先做 QK 乘结果再与 V 乘,先做 KV 乘结果再与 Q 乘。
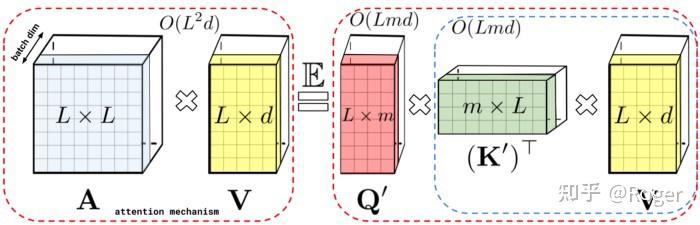
与 Linformer 和之前的稀疏注意力技巧不同,Performer 设计的巧妙之处在于它不显式地计算和存储注意力矩阵 A,因此避免了的开销。
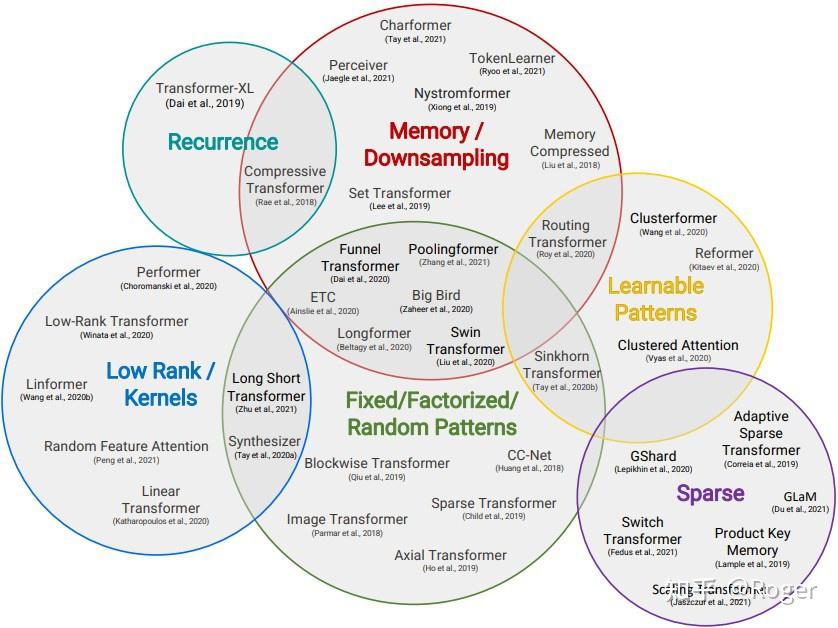
下图包括了当下大多数相关的优化工作。
各个模型之间的关系图如下:
那么,如何选择合适的模型呢?来自 Google 的一项工作关注于评估具有不同模式的较长输入序列的模型性能,他们用6个不同的任务从6个不同的角度来评估这些模型。
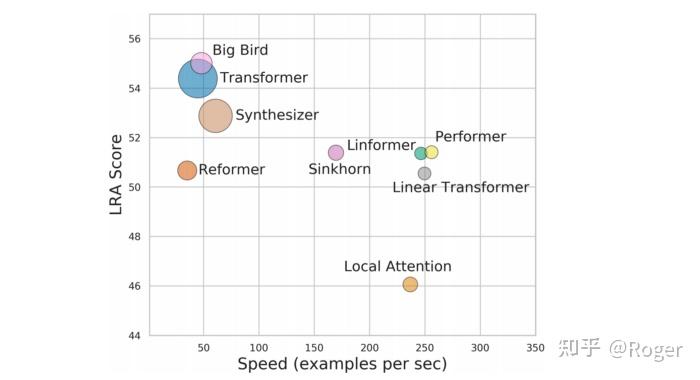
总的来说,这些模型在不同的任务上有不同的性能表现。一般基于 low-rank 和 kernel approximation 的方法(如 Performer,Linformer,Linear Transformer)在推理速度,任务表现及内存占用方面表现出更好的平衡性。
除了模型层面的优化,还有很多工作关注在架构及应用层面的优化。推理加速方面有像 NVIDIA的 Faster Transformer 和腾讯的 Turbo Transformer 等致力于提升推理性能的工作。
Faster Transformer 不修改模型架构而是在计算加速层面优化 Transformer 的 encoder 和 decoder 模块。做的事情包含:
用 Transformer的 encoder 阶段(即 BERT)做 benchmarking 的结果显示:Faster Transformer 在小的 batch size 及序列长度时可以带来3倍的加速;在大 batch size 及序列长度时,利用 INT8-v2 量化可以带来5倍的加速。

对于大 batch size 和序列长度,EFF-FT (Effective FasterTransformer) 和 FT-INT8-v2 都带来了 2 倍的加速。同时使用 EFF-FT 和 INT8-v2 相比 FasterTransformer FP16 可以带来大约 3.5 倍的加速。

Decoder部分,与 TensorFlow 相比,FT-Decoder 算子提供了1.5~3倍的加速,FT-Decoding 算子提供了4~18倍的加速。
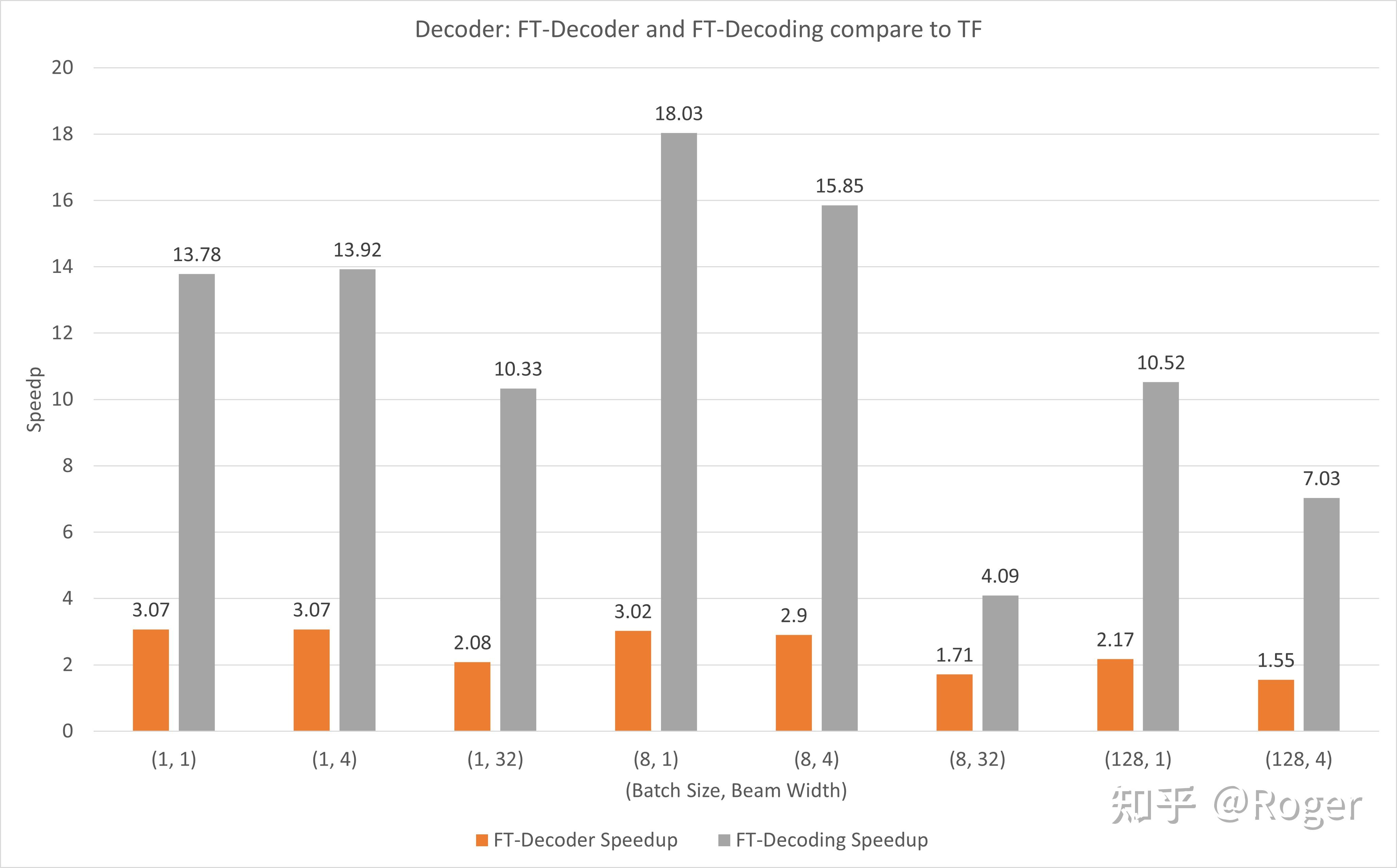
Turbo Transformer 是另一个专注于提高 Transformer 推理性能的项目,它由 computation runtime 及 serving framework 组成。加速适用于 CPU 和 GPU,最重要的是,它可以无需预处理便可处理变长的输入序列。一些要点如下:
Turbo Transformer 的实现与 Pytorch、Tensorflow 和 Faster Transformers 相比,Turbo Transformer 总的来说实现了更高的 QPS/throughput。
就固定长度的输入来说,Turbo Transformer 的 runtime 大约比 XLA 和 ONNXruntime 快10%,但比 Faster Transformers 和 TensorRT 要慢越10%。因为 TensorRT 需要offline tuning 过程,在此期间它可以为 GEMM kernel 选择最优参数且可能识别出对于非 GEMM kernel 来说最优的 CUDA 线程块大小。
欢迎关注公众号:机器学习算法之路,文章会第一时间发布在公众号上,不定时迁移到知乎。
Copyright © 2002-2022 首页-焦点娱乐-注册登录入口 版权所有 备案号:ICP备********号






