
深度学习的目标是通过不断学习改变网络参数,使得参数能够对输入做各种非线性变换拟合输出,本质上就是一个函数去寻找最优解,所以如何去更新参数是深度学习研究的重点。通常将更新参数的算法称为优化器,通过算法去优化网络模型的参数。
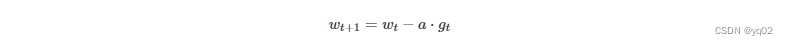
动量是模拟物理中的概念。一般而言,一个物体的动量指的是这个物体在它运动方向上保持运动的趋势,是物体的质量和速度的乘积。
动量优化方法是在梯度下降法的基础上进行的改变,具有加速梯度下降的作用。一般有标准动量优化方法Momentum、NAG(Nesterov accelerated gradient)动量优化方法。
Momentum
使用动量(Momentum)的随机梯度下降法(SGD),主要思想是参数更新时在一定程度上保留之前更新的方向,同时又利用当前batch的梯度微调最终的更新方向,通过积累之前的动量来加速当前的梯度。
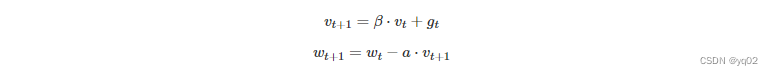
NAG
牛顿加速梯度(NAG, Nesterov accelerated gradient)算法,是Momentum动量算法的变种。
自适应学习率优化算法针对于机器学习模型的学习率,传统的优化算法将学习率设置为常数或根据训练次数调节学习率。极大忽视了学习率其他变化的可能性。因此需要采取一些策略自适应更新学习率,从而加快模型训练速度。
目前的自适应学习率优化算法主要有:AdaGrad算法,RMSProp算法,Adam算法以及AdaDelta算法。
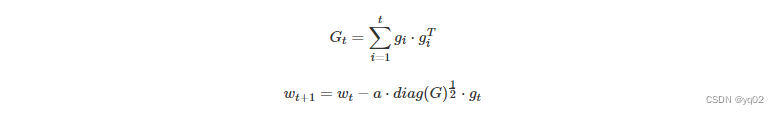
AdaGrad 基于平方梯度之和的倒数的平方根来缩放每个参数的学习率。该过程将稀疏梯度方向放大,以允许在这些方向上进行较大调整。在具有稀疏特征的场景中,AdaGrad 能够更快地收敛。
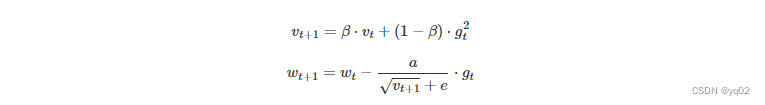
RMSprop其理念类似于 AdaGrad,但是梯度的重新缩放不太积极:用平方梯度的移动均值替代平方梯度的总和。RMSprop 通常与动量一起使用,可以理解为 Rprop 对小批量设置的适应。
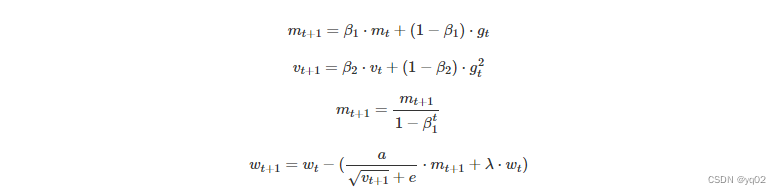
激活函数(activation function)又称非线性映射函数,是神经网络中中最主要的组成部分之一。
数据的分布绝大多数是非线性的,而一般神经网络的计算是线性的,引入激活函数,是在神经网络中引入非线性,以此来模拟复杂的非线性关系,强化网络的学习能力。
sigmoid函数也称Logistic函数,取值范围在(0, 1)之间,可以将网络的输出映射在这一范围。用于将一个实值输入压缩至[0,1]的范围,也可用于二分类的输出层。
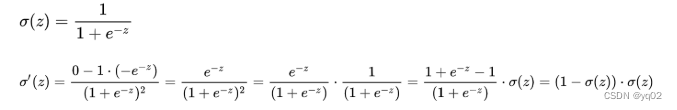

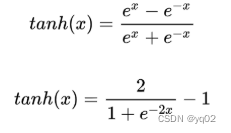
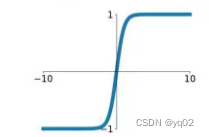
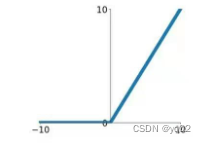
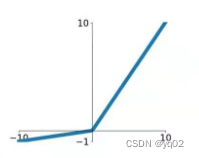
与 ReLu 相比 ,leak 给所有负值赋予一个非零斜率, leak是一个很小的常数,这样保留了一些负轴的值,使得负轴的信息不会全部丢失.
ELU
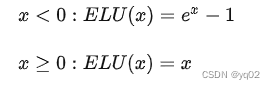
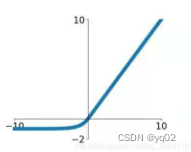
平方损失(预测问题)、交叉熵(分类问题)、hinge损失(SVM支持向量机)、CART回归树的残差损失
交叉熵(cross-entropy)刻画了两个概率分布之间的距离,更适合用在分类问题上,因为交叉熵表达预测输入样本属于某一类的概率。
平方损失函数数理统计中演化而来,均方误差是指参数估计值和参数真实值之差平方的期望值。在此处其主要是对每个预测值与真实值作差求平方的平均值
1、数据增强或扩充数据集;
2、添加正则化项;
3、dropout;
4、Batch Normalization
Batch Normalization 的处理对象是一个batch的样本, Layer Normalization 的处理对象是单个样本。Batch Normalization 是对这批样本的同一维度特征做归一化, Layer Normalization 是对这单个样本的所有维度特征做归一化。
BN

倾向于认为同一位置的特征的同一维度的信息应该具有相同的分布,也可以认为同一位置的特征具有相同分布。
BN优点
1、加快神经网络的训练时间。BN强行拉平了数据分布,可以让收敛速度更快。
2、BN能够动态的调整数据分布,能容忍更高的学习率和简化初始化权重。
3、可以支持更多的损失函数。有些损失函数在一定的业务场景下表现的很差,就是因为输入落入了激活函数的死亡区域——饱和区域。而BN的本质作用就是可以重新拉正数据分布,避免输入落入饱和区域,从而减缓梯度消失的问题。
4、提供了一定的正则化的作用,可能使得结果更好。BN在一定的程度上起到了dropout的作用,因此在适用BN的网络中可以不用dropout来实现。
BN缺点
(1)BN是在batch size样本上各个维度做标准化的,所以size越大肯定越能得出合理的μ和σ来做标准化,对于batch_size的大小较敏感;
(2)在训练的时候,是分批量进行填入模型的,但是在预测的时候,如果只有一个样本或者很少量的样本来做inference,这个时候用BN显然偏差很大,例如在线学习场景。
(3)对于序列网络(RNN、lstm等模型)的效果不好。因为输入序列长度是不一致的,造成多样本维度都没法对齐,所以不适合用BN。
LN
倾向于认为一个样本内部的所有feature是相似的,可以直接在样本内各个维度上norm。这一假设在nlp任务中比较得到明显。一个句子的各个特征就是各个字词处理后得到的,基本是相似的。但假如输入特征是类似年龄,性别,身高这种多个不同特征concat起来的,再直接求样本内部的norm,由于各个feature的分布不一样,就会存在很大的问题。
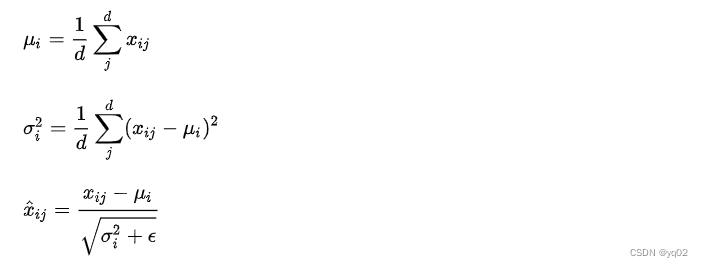
LN优点
(1)Layer Normalization是每个样本内部做标准化,因此对batch_size的大小并不敏感。
(2)LN比较适合NLP任务.
Copyright © 2002-2022 首页-焦点娱乐-注册登录入口 版权所有 备案号:ICP备********号






